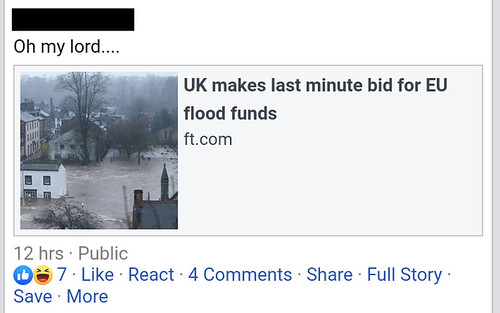
A few days ago, during a period of severe flooding across many parts of England and Wales, caused by storms Ciara and Dennis, one of my friends shared this Financial Times story, UK makes last minute bid for EU flood funds, on Facebook:
Obviously, it was a timely item, and relevant to many of those affected. and clearly related to recent Brexit developments.
Or was it?
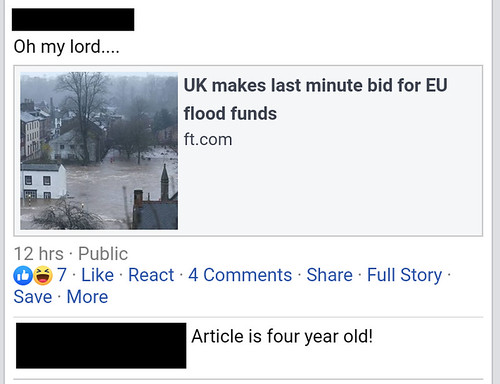
A mutual friend soon responded:
As you can see, they pointed out that the story was actually four years old.
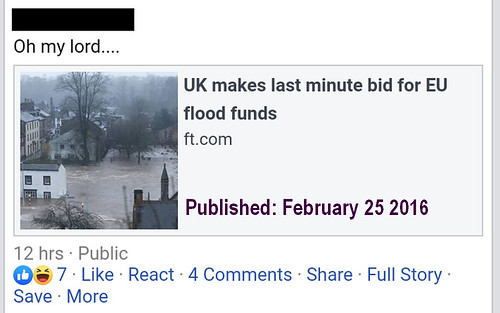
Facebook could prevent well-intentioned posts of such stale news from misleading people, and subtly discourage people from repeating them, by including the original publication date in their preview, something like this:
There are a number of ways they could obtain the publication date, such as from the shared page’s meta headers, and if no date is available they could even warn “no date specified, please check source”.
Of course, this won’t stop bad actors from publishing stories on web pages with deliberately misleading metadata, nor the inept from accidentally doing so, but Facebook are reportedly downgrading unreliable sources anyway, so that’s just another factor to add to their criteria.
And it’s not just Facebook, but Twitter and other social media services, that could do this.
Over the last few months, I’ve been in discussion with the BBC, encouraging them to make some of their content available under and open licence so that it can be used on Wikipedia. As an experiment, they’ve agreed to open licence a selection of audio “snippets” of notable people talking, from certain of their radio programmes. I uploaded the first three yesterday to Wikimedia Commons. For example, you can listen to the voice of former president of Ireland, Mary Robinson.
This is part of a wider project which the BBC launched today, in which they will not only be donating many more such extracts, but using them and the corresponding metadata, added to Wikidata by volunteers (an example of crowdsourcing), to identify other recordings in their archives, by the same speakers.
The idea is to let Wikipedia readers find out what the people we write about sound like [..] It’s great that we can hear the voices of people like Gandhi and Alexander Graham Bell, but what about all the other historic figures, whose voices are lost forever? We shouldn’t let that happen when we have the technology and resources so easily available. Sure, some of our subjects are known for media appearances, but those aren’t necessarily available globally nor under an open licence.
Andy’s original post was spotted by Tristan and passed around R&D. Our first thought was, “we’ve got lots of voices”. Our second thought was, with some adjustment this could be a useful hook for institutions like the BBC and beyond with large, digitised audio archives but sparse metadata and no way to know who’s speaking in them.
As part of the project, I’m helping them to run an event, “Speakerthon”, in London, on Saturday 18 January 2014, 10am – 5pm, where volunteers will be invited to help select and upload more audio files – and of course to add them to articles. There will also be a free guided tour of the venue, Broadcasting House. The event needs to be on BBC premises, as we’ll have exclusive access to their internal systems, to extract high-resolution audio. There’s an Eventbrite page for the event, where you can sign up. I hope to see some of you there.
[This post is rather overdue. Apologies to those of you who’ve been waiting for it.]
Saturday
Saturday at Wikimania started with an interesting plenary by Wikimedia Foundation Chief executive Sue Gardner, whom I’d had the pleasure of meeting, when I produced and engineered the live-streaming of a Wikimedia-UK board meeting, from the British Library in November 2011.
After lunch, it was my turn to face the spotlights I gave a presentation on the development of, and my work with, QRpedia, as part of a workshop I led with Lori Byrd Phillips and John Cummings, who have deployed QRpedia respectively at the Children’s Museum of Indianapolis, and as part of Monmouthpedia. After they had both spoken, we led the participants in hands-on exercise to create QRpedia QR codes, which they will hopefully in their home towns around the world. One participant tweeted:
this qrpedia session has, thus far, been the least schizophrenic and most concretely useful bit of #wikimania
We then had a mad dash to the theatre next door, to hear the closing plenary, by the Official Archivist of the United States, David Ferriero (I’d met him at the launch event and found him both approachable and witty. He wouldn’t let us have back their copy of Magna Carta, though). His speech was both complementary to Wikipedians and very inspiring; I do recommend you watch this video of it:
Then, we all piled outside for a group photo. See if you can find me!
Image by Adam Novak, CC-By-SA
A spare couple of hours gave time to return to the hostel, which I did by taking a meandering walk, freshen up, a then take another long walk, trough a part of town new to me, past many embassies, to Dupont Circle, for the closing party, with more plentiful free food and beer. The former was delicious, the latter as mediocre as I was sadly coming to expect. Yet another long walk got me to my bed.
Sunday
Though that formally ended the conference, the next day was given over to an unconference. I attended a useful session on browser tools to assist power-editing, then led a session on “Templates (Infoboxes): rationalisation and metadata emission” (trust me, that will mean something to technically-minded Wikipedia editors). This was one of the Wikimania’s highlights for me; not because I led it, but because the attendees gave me answers to some issues that had been vexing me for some time, and have continued since to work collaboratively with me, on-line, to resolve them. I also got to meet “Quarl” , who some years earlier had helped me immensely, by doing the coding of an idea I’d had, which became the template (“{{Coord}}“) now used over a quarter of a million times on the English Wikipedia (and many more in other languages) to display coordinates and emit them as metadata (a ‘geo’ microformat). These are used by partner organisations, like Google (for the Wikipedia layer on their maps) and by Yahoo. And I hadn’t even realised Quarl was at Wikimania!
The flip side, though was that the unconference was poorly attended, and petered out, so after lunch, I sloped off and decided to visit some of the museums I’d thought I would have to miss out on. I first called at the Smithsonian’s Museum of American History, specifically to see their three steam locomotives, the earliest of which, the John Bull, was made in England in 1831. They also had a Washington streetcar and a vehicle from the Chicago “L” overhead railway, plus several road vehicles. I then went over to the National Archives, where I saw not only the aforesaid copy of Magna Carta, but also the three “stars” of their exhibition, the original Declaration of Independence, the Constitution, and the Bill of Rights.
My next call was the Old Post Office, whose tower is available to visit, giving splendid views over all of Washington, and Ronald Reagan Airport in neighbouring Virginia. It also allowed me to see a horrible storm brewing over Arlington Cemetery, so when I left I headed straight for my hostel, and made it just before a downpour started.
Once the rain had passed, I had a last couple of beers in another local bar, part of the Capitol City Brewing Company group, whose beer is brewed locally. I tried the “Amber Waves” and “Pale Rider” ales, which were good by local standards.
Monday
I was not sure what to do with my last day in Washington, but luckily was persuaded to visit the ‘other’ Smithsonian Air and Space Museum, the Steven F. Udvar-Hazy Center near Dulles Airport. With John Cummings, I took a long bus ride to the airport, then he and I and some other Wikipedians shared a short taxi ride to the Museum. Wow. I got to stand next to the Space Shuttle ‘Discovery’ (admittedly, I’d seen it before, but only as a point of light, transiting in orbit from over Ireland to over Germany, viewed from my front garden!), a French Concorde, a Blackbird spy plane and, some unique German oddities from the last weeks of WWII, and, chillingly Enola Gay, the single vehicle that has killed more people than any other in our planet’s history.
We then had to take a shuttle bus to the airport, a bus back to Washington, pick up our bags from the hostel (the museum’s own publicity material said we couldn’t take luggage to the museum with us; annoyingly that turned out to be untrue, but caused us to waste over two hours), then take another bus back to the airport.
The flight home took off at dusk, and from my window seat I saw New York, Long Island and Cape Cod, all lit up. I then slept like a log until we were over Ireland. My trip home was really smooth. The Heathrow Express train to London, my tube train, my train home from Marylebone, and my bus from central Birmingham to my house were each waiting for me as I arrived and departed a soon as I boarded. It was like clockwork. The next day I slept late, but had no jetlag.
Conclusion
I confess I made my first trip to the USA expecting not to like it; for it to be too brash and aggressive. I was wrong. I loved it, and I’d go back tomorrow. The people were fantastic, and I barely scratched the surface of the cultural and historic interest Washington has to offer, let alone the rest of that vast country.
Wikimania was fascinating. I met so many people I’d corresponded or worked with online or who were new to me, and I continue to chat electronically with many of them. I’m buzzing with ideas for things we can do on, and with, Wikipedia.
But most of all, I remember a Wikipedia editor who asked for a volunteer to push his wheelchair round the Capitol tour. He was from Israel, and the guy pushing his chair, with whom he was sharing a lot of laughter, was from Iran. Enough said.
I often receive emails with signatures (footers; also known as “sigs”) like this one:
—
John Doe
Director of Flying Cars, Acme Ltd.,
A: 21, Example Street, Birmingham, B1 1AA
E: john.doe@example.com
T: 0121 555 5555
M: 05555 555555
W: www.example.com
(that first line is the standard sig separator of “dash dash space return”)
It’s irritating, if I want to add the sender to my address book, to have to copy’n’paste each item separately.
It seems to me that it should be possible for mail clients, such as Google Mail, to parse such sigs, and allow the user — after making any necessary edits — to add them to their electronic address books, without needing vCard (.vcf) file attachments or hCard microformat markup (which is not possible in plain-text e-mail).
It would need some agreement (or declaration by fiat) of which short codes to use:
and which properties can be plural. It might be determined that the first line should be the name; the second the job title/company — but, as users would be offered an “edit” option before saving the data, that’s not a deal-breaker.
Some thought would need to be given to internationalisation, also: do the above abbreviations make sense to speakers of, say, German or French? What about Japanese or Chinese speakers?
Alternative
Even without the labels:
—
John Doe
Director of Flying Cars, Acme Ltd.,
21, Example Street, Birmingham, B1 1AA
john.dow@example.com
0121 555 5555
05555 555555
www.example.com
it should be possible to scrape some data (e-mail address, phone numbers, website, name if on first line) from a sig.
Over to you
Does anyone fancy writing a demonstrator plug-in to parse such sigs, for an extensible mail client such as Thunderbird, or a browser like Firefox or Chrome? Do such things already exist anywhere?
I’ve just started using the “Twitter Blackbird Pie” plugin to embed tweets into WordPress posts (I use the self-hosted wordpress.org package). You can see an example below:
[blackbirdpie id=”66835851316957185″]
It’s fantastic — no more taking screen captures, cropping and uploading; or faffing about manually constructing links. All I have to do is include the magic code [blackbirdpie id="66835851316957185"] with the ID of the tweet (in the above example, taken from http://twitter.com/pigsonthewing/status/66835851316957185) as the id parameter value.
However, there are a few ways in which the plugin could be improved.
hCard microformat
Firstly, add an hCard microformat to emit details of the cited tweeter as metadata, by changing, for example (inline styles omitted for clarity):
with the addition of three class attributes: “vcard”; “nickname URL” and “fn”.
Citation
Next, instead of wrapping the contents of the tweet in a span, wrap it in a semantically-appropriate blockquote element, by changing:
<span>Blogging about a Blackbird.</span>
to:
<blockquote cite="http://twitter.com/pigsonthewing/status/66835851316957185">Blogging about a Blackbird.</blockquote>
and styling to maintain the current visual presentation.
Separating links
When viewed with CSS disabled, the tweet’s actions (“Reply”, “Retweet”, “Favorite”) run into each other.
To improve accessibility and usability, either add white space between them, or, better, mark them up as a list, styled to display in-line, unbulletted, again looking like they do at present.
White space
There is more white space above then below the embedded tweet, above. A little more padding below it would improve readability.
COinS
Finally, consider adding COinS mark-up, so that details of the cited tweet are emitted as metadata.
Invitation
I hope the authors of the plug-in, Themergency.com, will appreciate and act on these suggestions. I’ll be inviting them to read and comment on this post. And I’ll be happy to help with developing any of the ideas suggested above.
This is my response to The London Assembly Health and Public Services Committee‘s consultation on an open data standard for information about public toilets [Googe Docs link]. Try not to giggle at the back — this is good stuff, and of great usefulness: imagine a mobile app which can tell you where the nearest open public toilet is, in the evening; or the nearest with ease of access, if you’re a wheelchair user; or the nearest which is free, if you have no change. And no, I don’t live in London, but this standard should be usable everywhere, in the UK or overseas.
Use vCard properties (“street-address”, “locality”, “region”, “country-name”) .
Postcode
Use vCard “postal-code” property. Do not restirct to the 8-character UK standard, without checking that this will work for overseas postcodes.
Unique identifier
Should be a URI; or at least be capable of being resolved to one.
Latitude/ Longitude
Specify that these are in WGS84, as used by vCard and common mapping services (other, incompatible, coordinate schema exists).
Easting/ Northing
Redundant (or computable) if coordinates used. Not available in vCard. If both are allowed, need to specify which has precedence in case of inconsistency.
Owner
Use vCard “agent” property, including postal address properties. Alternatively, have a singe URI to a separate vCard record for the owner.
Gender, children, RADAR, other multi-choice properties
Use the vCard “category” property, which is plural, with an agreed vocabulary, where absence means no; alternatively have the vocabulary include negative values, and assume absence to mean “not known”.
Is it inside a shop / café / pub?
Use the vCard “category” property, with an agreed vocabulary, applied to the owner.
Opening hours
Use the proposed model, inside the vCard “note” property. Watch for emerging “opening hours” schema elsewhere.
And move all free-text options to the vCard “note” property, which is plural, using a prefix to distinguish them.
If the use of vCard is not possible, I would still mirror vCard properties and property-names as closely as possible, especially for addresses, in order to ensure ease of interoperability.
I am happy to elaborate on these points if that would be helpful.
Disclosure: I’m a contributor to the v4 vCard revisions.
Update: At the request of staff from The London Assembly, I’ve updated their Google Doc (linked above), mapping fields to the vCard standard.
That’s a neat idea; it would be a collaborative move on behalf of the City (disclosure: they employ me, but these are my own thoughts), and would be of interest to the general public.
However, the time and effort spent doing do so would only be of use to that one site and its visitors.
A better solution, perhaps, would be for the City Council (and anyone making archives of images available in an open manner) to invest the equivalent effort in adding metadata (about the subject, location, date and licence, which should of course be open) to suitable images, and for third-party sites to then parse that metadata, and import the images. Of course, such an import could also be done by individuals, on an “as needed” (or more likely “as desired”) basis, as a crowd-sourcing activity.
My picture of the City of Birmingham's pre-1974 coat of arms, hosted on Flickr, where it has lots of lovely, rich metadata and an open licence
The question is — what is the best way to include such metadata — internal to the image, in a format like EXIF? As scrapeabe text, on a page displaying the image, like Flickr’s metadata, such as tags? Or on such a page, but using a parsable microformat, or as a separate resource, such as RDF? Or a combination of these?
And are any third-party sites already indexing or aggregating images and their metadata in this way? If not, why not? Do we have a chicken-and-egg problem?
<span class="citation book">Mabbett, Andy (2010). <i>Pink Floyd - The Music and the Mystery</i>. London: Omnibus,. ISBN <a href="...">9781849383707</a>.</span>
<span class="Z3988" title="ctx_ver=Z39.88-2004&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook&rft.genre=book&rft.btitle=Pink+Floyd+-+The+Music+and+the+Mystery&rft.aulast=Mabbett&rft.aufirst=%26%2332%3B%26%2332%3BAndy&rft.au
=Mabbett%2C%26%2332%3B%26%2332%3B%26%2332%3BAndy&rft.date=2010&rft.place=London&rft.pub=
Omnibus%2C&rft.isbn=9781849383707&rfr_id=info:sid/en.wikipedia.org:Pink_Floyd_The_
Wall_(film)"><span style="display: none;"> </span></span>
And here it is again, with line breaks inserted for clarity:
<span class="citation book">Mabbett, Andy (2010). <i>Pink Floyd - The Music and the Mystery</i>. London: Omnibus,. ISBN <a href="...">9781849383707</a>.</span>
<span class="Z3988" title="ctx_ver=Z39.88-2004
&rft_val_fmt=info%3Aofi%2Ffmt%3Akev%3Amtx%3Abook
&rft.genre=book
&rft.btitle=Pink+Floyd+-+The+Music+and+the+Mystery
&rft.aulast=Mabbett
&rft.aufirst=%26%2332%3B%26%2332%3BAndy
&rft.au=Mabbett%2C%26%2332%3B%26%2332%3B%26%2332%3BAndy
&rft.date=2010
&rft.place=London
&rft.pub=Omnibus%2C
&rft.isbn=9781849383707
&rfr_id=info:sid/en.wikipedia.org:Pink_Floyd_The_Wall_(film)">
<span style="display: none;"> </span>
</span>
Some people complain that the presence of COinS bloats pages which have many references: for instance, note that my name, the publisher (“Omnibus“), publishers’ location (“London“), ISBN etc., plus the article’s URL, are repeated in the title attribute of the span which has class=”Z3988″, used to denoted COinS metadata.
<span class="citation book hCite"><span class="author vcard"><span class="fn">Mabbett, Andy</span></span> (<span class="dtstart">2010</span>). <i class="work">Pink Floyd - The Music and the Mystery</i>. <span class="publisher vcard"><span class="label">London</span>: <span class="fn org">Omnibus</span>,. ISBN <a href="..." class="isbn">9781849383707</a>.</span>
Despite adding semantic class names (hcite, author, vcard, fn, dtstart, work, publisher, label, org, isbn), and span elements on which to hang some of them, this is markedly more compact (down from 614 to 363 characters, excluding the redacted URL), easier for humans to read, doesn’t require lots of escaped characters and doesn’t repeat any of the data. The processing burden on Wikipedia’s servers would also be lower.
The primary tool used for accessing COinS metadata is Zotero; whose authors have already indicated to me (in conversation) an interest in parsing such a microformat.
Discussions of what to include in the proposed citation microformat on the microformats mailing list stalled sometime ago, but that doesn’t stop an organisation like Wikipedia from developing a draft, implementing it, and presenting it to the wider web community for discussion, improvement and ratification. The draft could have 1–1 mapping with the properties in COinS, to facilitate ease of conversion by parsing tools.
I’m migrating to a WordPress.org installation. Please bear with me — and the crappy header graphic — while I fiddle under the bonnet.
The links that used to be on my home page are now on the new about page. I’ve migrated posts and comments from my old blog, Mabblog, and closed comments there. I’ll be using this site to blog from now on.
Recommendations for a better theme, useful plug-ins and the like all welcome. I’d particularly like to be able to write my own HTML header and footer (without using PHP), and to add & improve metadata headers.
I’m grateful to Bruce Lawson of Opera for alerting me to discussion of the <time> element on the HTML5 mailing list (where I’ve posted a copy of this blog post) and encouraging me participate; and indebted to him for the engaging discussions which have led me to the ideas expressed below. So please blame him if you don’t like what I have to say 😉
I’ve read up on what prior discussion I can find on that mailing list; but may have missed some. I’ll be happy to have anything I’ve overlooked pointed out to me.
I have considerable experience of marking up dates in microformats, both for forthcoming events on the West Midland Bird Club’s diary pages; and for historic events, on Wikipedia and Wikimedia Commons.
I’ve been a staunch and early critic of the accessibility problems caused by abusing the <abbr> element for things like machine-readable dates (as has Bruce). The HTML5 time element has the potential to resolve that problem, but only if it caters for all the cases in which microformats are — or could potentially be — used.
It seems to me that there are several outstanding, and overlapping, issues for <time> in HTML5, which include use-cases, imprecise dates, Gregorian vs. non-Gregorian dates and BCE (aka “BC“) dates. First, though, I should like to make the observation that, while hCalendar microformats are most commonly used to allow event details to be added to calendar apps, and that that use case drove their development, they should not be seen simply as a tool to that end. I see them, and hope that others do, as a way of adding semantic meaning to mark-up; and that’s how I view the “time” element, too. Once we indicate that the semantic meaning of a string of text is date, it’s up to other people to decide what they use that for — ”let a thousand flowers bloom”, as the adage goes.
Use-cases for machine-readable date mark-up are many: as well as the aforesaid calendar interactions, they can be used for sorting; for searching (“find me all the pages about events in 1923″ — recent developments in Yahoo’s YQL searching API (which now supports searching for microformats) have opened up a whole new set of possibilities, which is only just beginning to be explored). They can be mapped visually on a “SIMILE” or similar time-line. They can be translated into other languages more effectively than raw prose; they can be disambiguated (does “5/6/09” mean “5th June 2009” or “6th May 2009”?); and they can be presented in the user’s preferred format (I might want to see “5th June 2009”; you might see “June 5, 2009″ — such presentational preferences have generated arguments of little-endian proportions on Wikipedia).
hCalendar microformats are already used to mark up imprecise dates (“June 1977”; “2009”). ISO8601 already supports them. Why not HTML5? Though care needs to be taken, it’s even possible to mark up words like “today” with a precise date, if that’s generated real-time, server-side.
The issue of non-Gregorian (chiefly Julian) dates is a vexing one; and has already caused problems on Wikipedia. So far as I am aware, there is no ISO-, RFC- or similar standard for such dates, other than converting them to Gregorian dates. It is not the job of the HTML5 working group to solve this problem; but I think the group should recognise that at some point a solution must be forthcoming. One way to do so would be allow something like:
<time schema="[schema-name]" datetime="[value]">[date in plain text]</time>
where the schema defaults to ISO 8601 if not stated, and the whole element is treated as simply:
[date in plain text]
if the schema is unrecognised; thereby ensuring backwards compatibility. That way, if a hypothetical ISO- or other standard for Julian dates emerges in the future, authors may simply start to use it without any revision to HTML 5 being required.
As for BCE dates, they’re already allowed in ISO 8601 (since there was no year 0, the year 3 BCE is given as -0002 in ISO 8601). I see no reason why they should be disallowed in <time> elements in HTML5. We wouldn’t, to take an extreme example, say that “<P>” can be used for paragraphs in English but not French; or paragraphs about literature but not music, so why make an effectively arbitrary limit on the dates which can be marked up semantically? Surely the use case for marking-up a sortable table of Roman emperors, should allow all such emperors, and not just those who ruled from 0001AD, to be included?
Coordinates
Another abuse of ABBR in microformats for coordinates: